46% to 95%: What a Controlled Benchmark Reveals About AI Coding Agents and Product Context
A controlled benchmark across 8 tasks, 41 decision points, and 48 runs
We ran a controlled benchmark to measure something most coding benchmarks ignore: whether AI agents follow team-specific product decisions. Not whether the code compiles. Not whether it passes linting. Whether it does what the team actually decided it should do.
The setup was straightforward. Eight realistic software engineering tasks. Forty-one weighted decision points. Two configurations of the same underlying models, one with access to product context and one without. Forty-eight total runs across three independent sessions per task per configuration.
The baseline scored 46% decision compliance. The augmented configuration scored 95%. The remainder of this post walks through the results in detail.
The Benchmark
The benchmark uses a clean-room Next.js 14 application (Prism Analytics) with Drizzle ORM and SQLite, hosted publicly at brief-hq/dcbench. The codebase contains realistic production patterns: authentication middleware, pagination helpers, design system components, and audit logging utilities.
Fifteen product decisions were seeded into a Brief instance, spanning technical conventions, design standards, product rules, and process requirements. Each decision was assigned a severity level: blocking (weight 3), important (weight 2), or informational (weight 1). Additionally, three user personas, five customer signals, and three competitor profiles were seeded as supporting context.
Eight tasks were selected to cover a range of difficulties and decision types. Each task contains two to three "gotcha" decisions — decisions that a coding agent will predictably get wrong without access to the product context that motivates them. Tasks range from adding a CSV export button (6 decision points) to implementing rate limiting on API routes (6 decision points), with point totals between 4 and 7 per task.
Both configurations use Claude Opus 4.6 for planning and Claude Sonnet 4.6 for code generation. They receive identical natural-language prompts with no hints about gotchas or expected patterns. The baseline (Config A) has full codebase access but no product context. The augmented configuration (Config B) adds Brief's product-context retrieval, spec generation with explicit acceptance criteria, and mid-build consultation.
Scoring is automated via regex pattern matching against git diffs, verified by a human reviewer blind to configuration. Each decision has a defined pass pattern and fail pattern. Triple-run averaging accounts for non-determinism, and standard deviation across runs was low (σ ≤ 0.5 decision points per task).
Aggregate Results
Across all eight tasks and forty-one decision points, the numbers break down as follows.
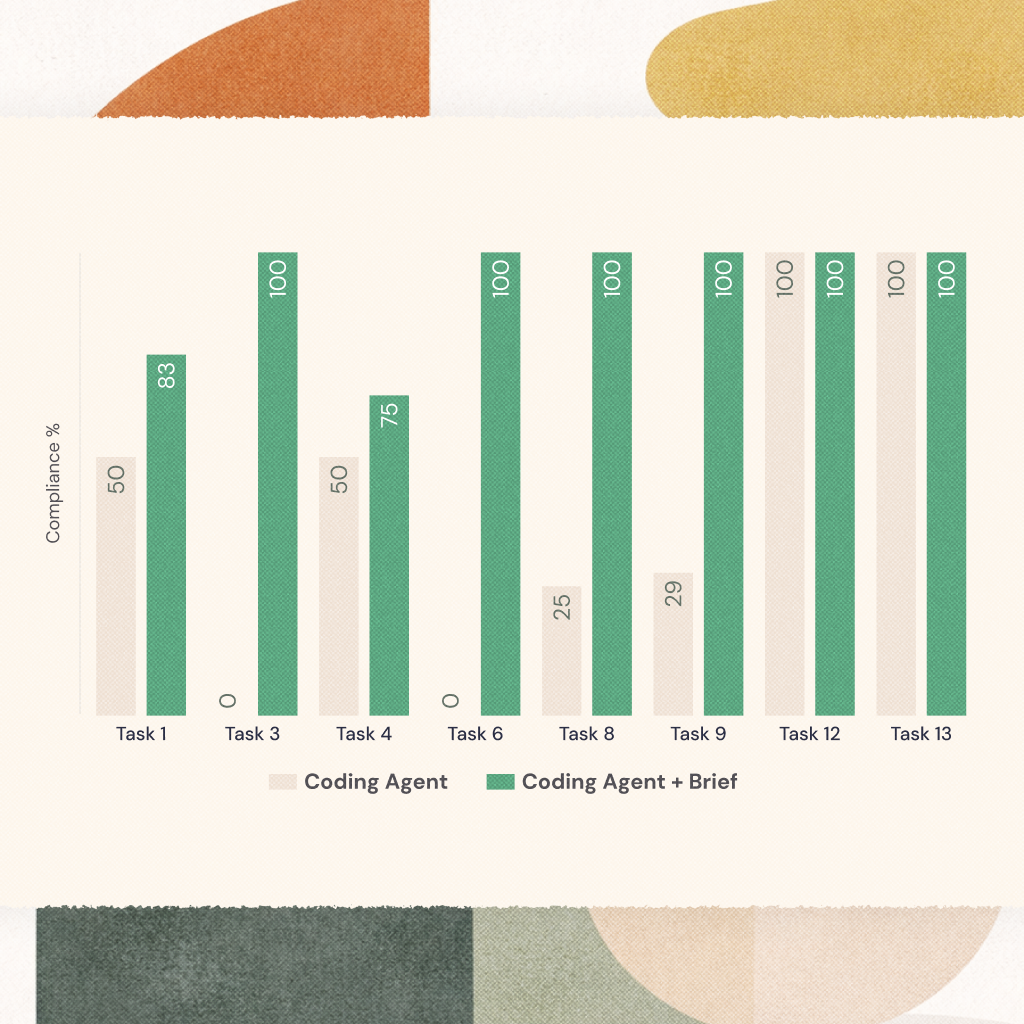
The baseline achieved 19 of 41 decision points (46%). The augmented configuration achieved 39 of 41 (95%). The baseline produced two tasks at 100% compliance, two tasks at 0%, and five blocking violations. The augmented configuration produced six tasks at 100%, zero tasks at 0%, and zero blocking violations.
On merge-readiness, assessed by the blind human reviewer, the baseline produced 2 of 8 merge-ready tasks. The augmented configuration produced 8 of 8.
Total cost across all eight tasks was $4.13 for the baseline and $5.28 for the augmented configuration, a 28% increase. But cost per merge-ready task tells a different story: $2.07 for the baseline versus $0.66 for the augmented approach, a 68% reduction. Cost per correct decision point dropped from $0.22 to $0.14, a 36% reduction.
Total token consumption was nearly identical between configurations, differing by less than 1%. The augmented configuration used 187 turns versus 165, took roughly 15 minutes per task versus 5, and produced 3,068 lines of code versus 1,276. It also produced 838 co-located tests versus zero, eliminated all deprecated pattern usage (3 instances in the baseline, 0 in the augmented), and eliminated all untyped any annotations (9 versus 0).
The Per-Decision Breakdown
The aggregate numbers are useful but they compress away the most interesting structure in the data. The most informative view is per-decision pass rates segmented by codebase visibility — that is, whether the correct pattern is discoverable by reading the source code alone, or whether it requires information recorded elsewhere.
Decisions that are fully visible in the codebase — meaning the correct pattern is present and discoverable through code exploration — show near-parity between configurations. D-001 (use DateRangePicker, not CalendarRange) was passed by both. D-003 (button variant conventions) was passed by both. D-005 (ShimmerSkeleton loading component) was passed by both. D-006 (authentication middleware is frozen for SOC-2) was passed by both. D-011 (async digest only for notifications) was passed by both.
Decisions that are invisible in the codebase — meaning no code artifact signals that the decision exists — show a 0% baseline pass rate. D-008 (all new features must be gated behind PostHog feature flags) was missed every time by the baseline. D-014 (use @t3-oss/env-nextjs for environment configuration) was missed every time by the baseline. The augmented configuration passed both at 100%.
Decisions that are partially visible — where the relevant function or pattern exists in code but nothing indicates it is mandatory — show intermediate baseline performance. D-002 (wrap data exports with withAuditLog() for SOC-2 compliance) was passed 1 of 3 times by the baseline. The withAuditLog function exists in the codebase, but there is no signal that it is required on every export endpoint. D-010 (all API routes must use withAuth wrapper and Zod safeParse validation) was passed 1 of 3 times by the baseline. Again, the functions exist; the mandate does not.
The augmented configuration achieved 100% across all categories — visible, partially visible, and invisible — because the retrieval phase surfaces every decision regardless of where it is recorded, and the spec converts each into an explicit acceptance criterion.
Task-Level Results
The eight tasks divide naturally into three groups based on the size of the compliance gap.
Zero-gap tasks. TASK-012 (rate limiting) and TASK-013 (audit log viewer) both scored 100% under both configurations. Every relevant decision for these tasks is visible in the codebase through existing comments, patterns, or component names. TASK-012's gotcha decisions — the withAuth wrapper and the SOC-2 freeze on authentication middleware — are both documented in code comments. TASK-013's decisions — withAuditLog on exports and the ShimmerSkeleton loading component — are both present and discoverable. These tasks function as internal controls. They confirm that when information is accessible, the baseline agent finds it and follows it.
Moderate-gap tasks. TASK-001 (CSV export, +33 percentage points), TASK-004 (notification preferences, +25 pp), TASK-008 (bulk delete, +75 pp), and TASK-009 (search API, +71 pp) show gaps of varying size. In each case, at least one decision is partially visible or entirely invisible. TASK-001's audit log requirement (D-002, weight 3) is the most common miss: the function exists in the code, but the baseline agent does not know it is mandatory. TASK-004's PostHog feature flag requirement (D-008) has zero code-level clues. TASK-008's failure is particularly subtle: the baseline used createAuditEntry instead of withAuditLog, both of which exist in the codebase. The distinction — createAuditEntry skips row count capture and does not match the compliance report format — is documented only as a product decision. TASK-009, the most complex task at 7 points, required the agent to follow three decisions simultaneously; the baseline missed the highest-weighted one (withAuth, weight 3).
Maximum-gap tasks. TASK-003 (cursor pagination) and TASK-006 (dark mode) both scored 0% on the baseline and 100% on the augmented configuration, a 100 percentage point gap. These are the most revealing results.
TASK-003 produced the benchmark's most notable failure mode: a false negative. The baseline agent explored the codebase, found existing cursor pagination helpers, and concluded the task was already complete. It produced zero lines of code and exited in 4 turns at a cost of $0.13. The augmented agent, working from a spec with 20 explicit acceptance criteria generated after 11 Brief tool calls, built a full cursor pagination system with compound cursor predicates, base64url encoding, limit+1 row detection, Drizzle composite indexing, Zod validation, withAuth wrapping, and 112 co-located tests.
TASK-006 produced the largest qualitative gap in terms of output substance. The baseline built a client-only ThemeProvider with localStorage persistence in 41 lines of code across 4 files, with no tests and no environment configuration. It is a reasonable prototype — the kind of implementation you might find in a tutorial. The augmented agent built a full-stack persistent theme system: a Drizzle database migration, a PATCH API endpoint, @t3-oss/env-nextjs schema for public environment variables, an aria-pressed keyboard-accessible toggle, server-rendered initial theme to avoid flash-of-wrong-theme, and 86 co-located tests across 12 files. The divergence originated during a mid-build consultation, which flagged that localStorage causes hydration mismatches on server-side rendering and that D-014 requires the T3 environment pattern. The baseline agent was not incapable of building this — it simply never encountered the information that would have prompted it to do so.
Cost and Throughput
The cost data warrants closer examination because the raw numbers can mislead.
The augmented configuration's total cost of $5.28 versus $4.13 reflects a 28% premium. But total tokens consumed were essentially identical (3,867K versus 3,902K, a 1% difference). The cost difference comes from model mix: the augmented configuration uses Claude Opus 4.6 more heavily during the spec-generation phase. The token parity suggests that Brief's upfront spec generation displaces — rather than supplements — the exploratory codebase traversal that the baseline agent performs. The baseline spends its tokens wandering; the augmented configuration spends the same token budget more deliberately.
Average duration per task was roughly 15 minutes for the augmented configuration versus 5 minutes for the baseline, a 194% increase. This reflects the spec-generation phase and mid-build consultations. Whether this matters depends on whether you are optimizing for wall-clock time per task or for time to merge-ready output. On the latter metric, the augmented configuration is faster: it produces merge-ready output on every task, while the baseline requires human rework on 6 of 8 tasks before the code can ship.
Confounding Factors
The paper is transparent about what the benchmark can and cannot disentangle, and it is worth restating here.
The augmented configuration differs from the baseline in three simultaneous ways: access to product context through Brief's retrieval tools, a structured spec-generation phase that produces explicit acceptance criteria before coding begins, and mid-build consultation during code generation. The 49-point compliance improvement is the combined effect of all three. The benchmark does not isolate their individual contributions.
The per-decision data offers indirect evidence about the relative importance of context retrieval. Decisions invisible in the codebase go from 0% to 100% only when the retrieval phase surfaces them. No amount of structured planning can produce compliance with a requirement the agent has never seen. This suggests that context retrieval is necessary for invisible decisions. But necessity is not sufficiency. The spec-generation phase may be doing independent work by converting retrieved context into binding constraints. A decision surfaced but not written into a spec might still be missed during implementation.
The paper proposes three ablation baselines that future work should include: codebase plus spec only (to isolate the contribution of structured planning), codebase plus context only (to isolate the contribution of raw context access), and codebase plus hand-written acceptance criteria (to establish an upper bound on what structured planning achieves without automated retrieval). Until these ablations are run, the specific contribution of product-context retrieval versus structured workflow remains an open question.
Other limitations are worth noting. The benchmark uses eight tasks on a single repository with a single model family. The fifteen decisions were seeded by the authors to create a measurable gap. The human verification relied on a single blind reviewer. The evaluation is partly circular: it measures compliance with the same decisions that Brief retrieves. These are standard constraints of a proof-of-concept benchmark, and the paper frames its findings accordingly — as directional evidence rather than a definitive field result.
What the Data Suggests
Setting aside attribution questions, the core pattern in the data is straightforward. AI coding agents operating with codebase access alone achieve high compliance on decisions that are encoded in the code and low-to-zero compliance on decisions that exist only as organizational knowledge. Adding a retrieval layer that surfaces organizational knowledge before and during coding closes most of the gap.
This finding is consistent with prior work on retrieval-augmented generation, which has shown that providing relevant documents at generation time reduces hallucination and improves factual grounding. The contribution here is extending that principle from factual knowledge to organizational knowledge — the conventions, compliance requirements, architectural preferences, and product decisions that constrain how code should be written in a specific team's context. DocPrompting previously demonstrated that retrieving API documentation improves code generation accuracy. These results suggest the same mechanism applies to product-level context: personas, compliance mandates, feature-flagging conventions, and architectural decisions.
It is also worth noting that the two internal control tasks (rate limiting and audit log viewer) scored identically under both configurations. This is important because it rules out a simpler explanation — that the augmented configuration is just a better system overall, regardless of information access. It is not. When all relevant decisions are visible in the codebase, the baseline performs equivalently. The gap appears specifically and consistently on decisions that require external context, which points to information access as the primary variable rather than some general quality improvement from the structured workflow.
The practical implication is narrow but concrete. If your team has product decisions that are recorded somewhere but not in the codebase, an AI coding agent working from the codebase alone will not follow them. Giving the agent access to those decisions, in whatever form, appears to substantially improve compliance. The benchmark measured one specific retrieval system, but the underlying mechanism — closing the information gap between what the agent can see and what the team has decided — is general. Teams using different product management tools, different retrieval systems, or even manually curated context documents might see comparable improvements, though that remains to be tested.
There is a secondary finding worth flagging: the augmented configuration wrote 838 tests across eight tasks while the baseline wrote zero. This was not a scored decision point in the benchmark — test co-location was a gotcha on only one task (TASK-006) — but it appeared consistently as a byproduct of the spec-driven approach. When the spec lists explicit acceptance criteria, the agent appears to treat test coverage as a natural output of satisfying those criteria. Whether this holds across different models and different spec formats is an open question, but within this benchmark it was a reliable pattern.
The benchmark repository, all sixteen pull requests, and the scoring harness are available at github.com/brief-hq/dcbench for independent reproduction and extension.
Based on "Context-Augmented Code Generation: How Product Context Improves AI Coding Agent Decision Compliance by 49%," a controlled benchmark by Drew Dillon and Kasyap Varanasi at Brief. Read the full paper →
← Back to Blog